Challenge 4 Fletcher Project
Project 4 Fletcher Project
A Glance At New York Times Science and Technology News
Story
The generation of technologies is rapidly changing. The hotness in the new technology attracts people and capital, meanwhile, some area is losing attentions, like physics or biology. When Dolly was born, genetic engineering was a hot topic and young generations were willing to study it, however, there were not enough positions to absorb so many new graduates, quite a lot of them need to tune majors to find jobs after graduation. At this time, computer science or data science become popular, it is common to hear that the market needs millions of professionals in data science. But no exception, data scientist some day will have to face the similar situation like biologists now.
With this motivation, I want to read history, see the trend of a frontier technology or science subject in the past decades from New York Times. With more data, like statistics of labor in different position, maybe we can see when a new tech generates, how many unemployment it will bring to the market. Futher with more source or analysis, maybe we can predict the year that AI occupies some positions.
Goal
In this project, I start the journey by finding the keywords abstracting from New York Times leading paragraphs in technology and science yearly from 1945 to 2017. Because the unemployment is related to companies, I did a sample of name entitites of Google using Word2Vec.
Data
Using New York Times Developers API, I got more than 8.35 million daily documents. Each document includes information of publication time, section, keywords, author, leading paragraph and etc., then using MongoDB mask to choose 3.76 million leading paragraph related to science and technology.
Figure 1. The statistics of Sci & Tech News in NYT
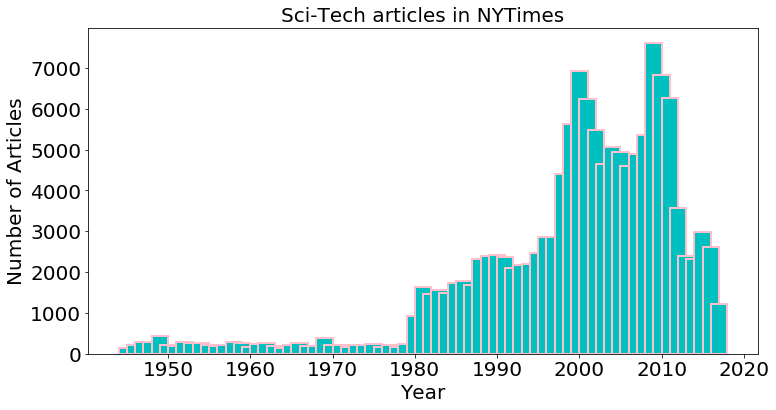
At first, I created a mask for section in science & technology, but after I checked the data after mask, I found that before Oct.10, 1980, there was no section of science & technology. As a reslut, I added keywords of science and technology to the mask, so if the document has anything related to science and technology, it will appear in my database.
Approach 1, the wordcloud of science & technology for decades.
Take year 2015 for example, with the science & technology related leading paragraphs, first applied word token, separating paragraphs to words, then with my own stopwords bag, deleting the words that could not represent the frontier technology. After the process, I tried stemming, which is to abstract the stem of the word, like take went, gone and goes all as go. But the attempt to make a word cloud with stemming gave strage result, appearing uncomplete words due to over-stem, besides, counts of word was reduced to 9k compared to 33k after stopwords.
Sci-Tech Leading paragraphs: 2,994
Total words: 157,000
After stopwords: 33,000
After stemming: 9,600
Word2Vect: 14,800
Word Cloud over Time With parameter of LDA, min_df=1, max_df=0.1
Figure 2. Word Cloud from 1945 - 2017.
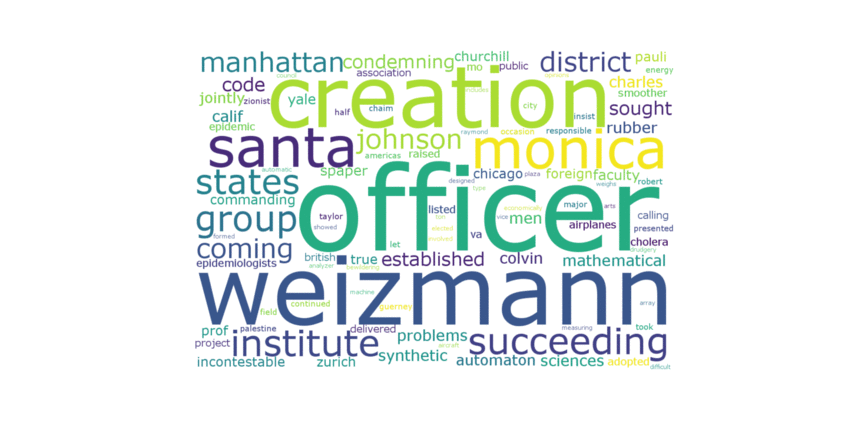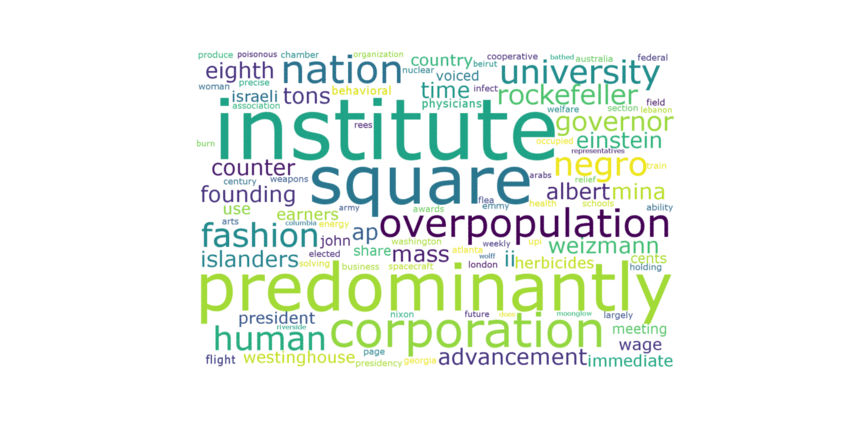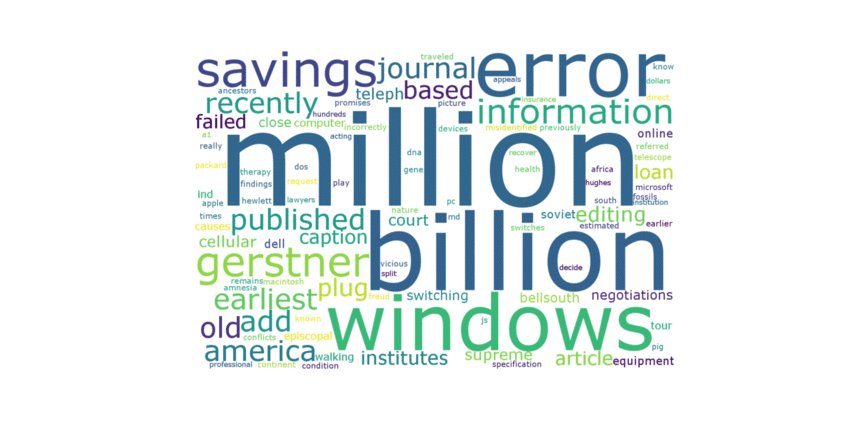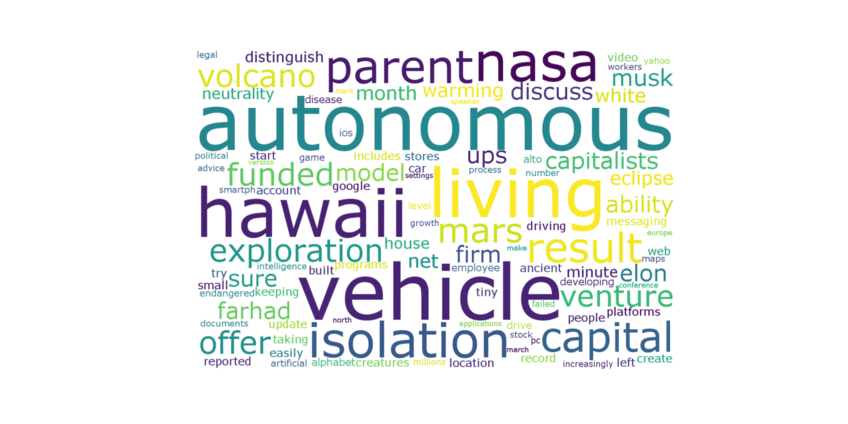
List of events from word cloud
| Year | Key Words | What happend |
| 1945 | atomic, war | Still in World War II |
| 1947 | war, photographic | |
| 1949 | wiener | Mr. Wiener: an American mathematician and philosopher, published a book Cybernetics: Or Control and Communication in the Animal and the Machine in 1948. |
| 1950 | norbert | |
| 1953 | battery, storage | |
| 1955 | aeronautical | Finding way to the moon |
| 1956 | enthnological | |
| 1958 | alamos, computer | Develop the computer technology |
| 1960 | cell, rabbits | |
| 1961 | radio, Schlesinger | Mr. Schlesinger: son and father, American historian, social critic, and public intellectual. |
| 1963 | stars | |
| 1964 | Artucio | Artucio: Uruguayan architect and architectural historian. |
| 1966 | mathematics | |
| 1970 | teleprompter | |
| 1971 | monoxide | |
| 1974 | infrared, television | |
| 1976 | bacteria | |
| 1980 | hopkins | |
| 1982 | egg, diary | |
| 1983 | saturn, computer | |
| 1984 | particle | |
| 1985 | comet, disk, binoculars | |
| 1986 | genetic,biotchnology | |
| 1988 | Kodak | |
| 1991 | computer, printer | |
| 1993 | windows | |
| 1994 | chip, computer, optic, communications | |
| 1995 | www, http | |
| 1999 | mars, simon, HP | |
| 2000 | fiber, optic, camera, dell, alamos | |
| 2001 | stem, embryos, cell, amazon, dell | |
| 2003 | gene | |
| 2008 | carbon | |
| 2009 | app, car, telescope, plant, ray | |
| 2010 | ipod, chip | |
| 2011 | smart, silicon, dioxide | |
| 2012 | web, sandy | |
| 2014 | Albert Einstein, psychology | |
| 2016 | cloud, car, trump | |
| 2017 | car, vehicle, Elon Musk, nasa |
word2vec on 2015
PCA n_components=2
w2v
Approach 2, clustering comparison.
Clustering Models:
KMeans versus WARD
n_clusters = 6
Figure 3. K-Means Clustering
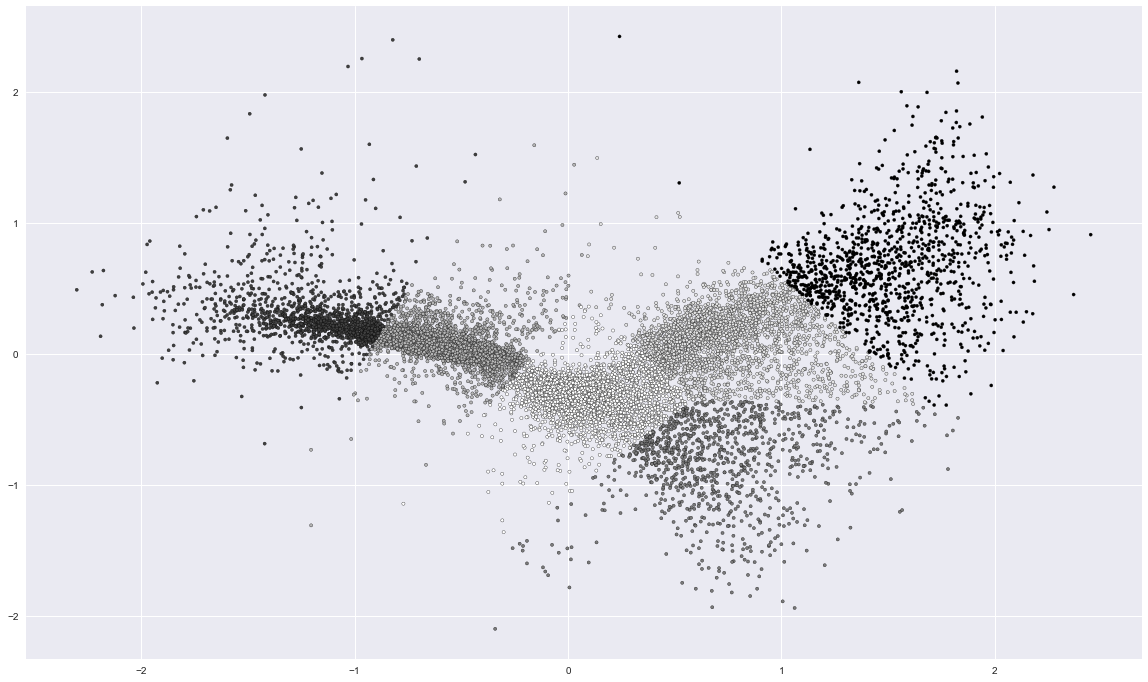
Figure 4. Ward Clustering
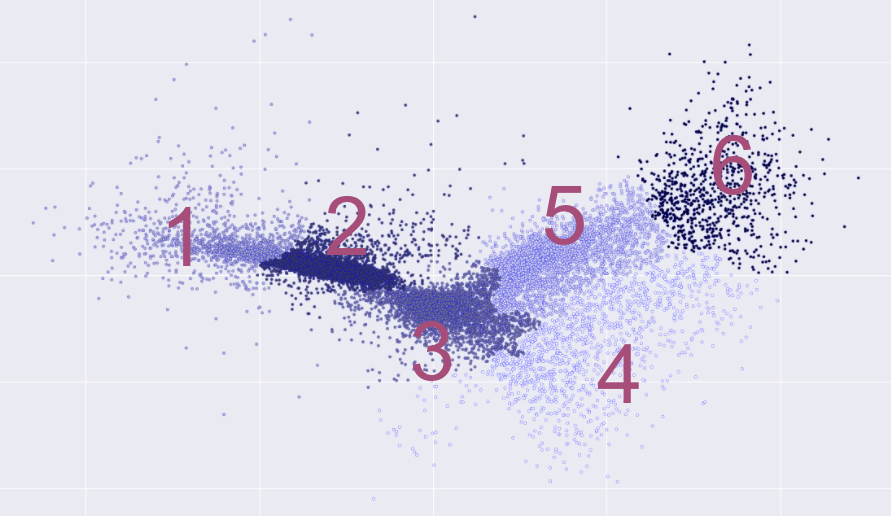
Possible groups
1: UPenn, NYU, Cornell, Yale, date
2: Navy, NJIT, Evangelist Catholic, locations
3: IPO, Exxon Mobil, Elon Musk, Mark Zuckerberg, gmail
4: biologist, excellence, Zajfman(Physicist), some first names
5: China, Paris, silicon, NASA, Amazon, Uber, Yahoo
6: economics, foundation, father, daughter-in-law
Approach 3, named-entity recognition of Google.
Google relationship extraction on 2017
document: 1215
words: 27,000
Figure 5. Google relationship

Reference
https://en.wikipedia.org/wiki/List_of_years_in_science
https://www.codeschool.com/blog/2016/03/25/machine-learning-working-with-stop-words-stemming-and-spam/
https://github.com/smilli/py-corenlp
http://lab.hakim.se/reveal-js/#/